Feature Engineering
Feature Engineering
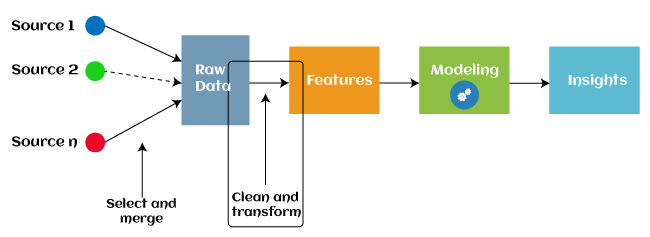
Feature engineering in the Data Preparation phase of machine learning refers to the process of transforming raw data into meaningful features that can improve the performance of machine learning models.
These features are variables or attributes used by the model to make predictions. Effective feature engineering can significantly enhance model accuracy and performance, especially in complex datasets.
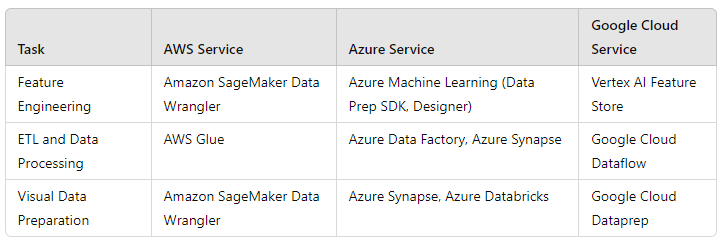
Tools on Cloud (AWS, Azure, Google)
Key Steps in Feature Engineering:
1. Handling Missing Data :
Techniques like mean, median, or mode imputation are applied to fill in missing values.
Example : If you have a dataset with missing temperature data, you can replace missing values with the average temperature.
2. Normalization and Scaling :
Features are normalized or scaled to ensure all variables are treated equally by the model.
Example : In an e-commerce dataset, the feature
price(in dollars) may be scaled between 0 and 1 to make it comparable with features likecustomer ratings(which are typically on a scale of 1-5).
3. One-Hot Encoding :
Converts categorical variables into a binary (0 or 1) format.
Example : For a dataset with a feature called
Product Category(like Electronics, Clothing, etc.), one-hot encoding transforms it into separate binary columns (Is_Electronics,Is_Clothing, etc.).
4. Feature Interaction :
New features are created by combining existing features.
Example : In a housing dataset, a new feature
Price_Per_Square_Footcan be created by dividingHouse PricebySquare Footage.
5. Time-based Features :
Extracting useful information from date-time data.
Example : From a
Purchase Datefeature, you could create new features likeDay of the Week,Hour, orIs_Weekendto capture seasonality or time-related trends.
Feature engineering is a crucial step in building a high-quality machine learning model. Properly designed features enable models to better capture the underlying patterns in the data.