Ensemble Methods: Bagging, Boost, Stack, Vote..
Ensemble Methods: Bagging, Boost, Stack, Vote..
Ensemble methods are a class of machine learning (ML) techniques that combine multiple models to improve the overall performance and accuracy of predictions.
The underlying principle is that combining different models can reduce the variance, bias, and error compared to using a single model.
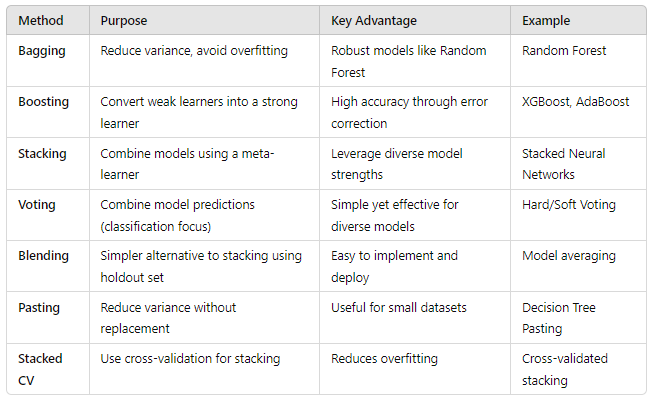
Here’s an overview of the various ensemble methods:
1. Bagging (Bootstrap Aggregating) :
- Definition : Bagging involves training multiple models on different subsets of the training data and then averaging or voting on their predictions.
- Objective : Reduces variance by averaging out the predictions of different models, making the final model less likely to overfit.
- How It Works :
- Data is sampled with replacement to create different training datasets.
- Each model is trained independently on a different dataset.
- For regression tasks, the predictions are averaged; for classification, a majority vote is used.
- Example : Random Forest is a popular bagging method that combines decision trees, each trained on different subsets of the data.
- Applications : Image classification, regression problems, fraud detection.
2. Boosting :
- Definition : Boosting involves training models sequentially, with each new model focusing on correcting the errors of its predecessor.
- Objective : Converts weak learners into a strong learner by focusing on the difficult-to-predict instances in the data.
- How It Works :
- Models are trained one after another, each model correcting the mistakes of the previous ones.
- Weights are adjusted for each training instance based on whether it was classified correctly.
- Final predictions are a weighted average or sum of all models.
- Examples :
- AdaBoost : Adjusts weights for instances that are misclassified.
- Gradient Boosting : Fits new models to the residuals of previous models.
- XGBoost, LightGBM, CatBoost : Optimized versions of gradient boosting, known for their speed and accuracy.
- Applications : Classification, regression, ranking problems, text processing.
3. Stacking (Stacked Generalization) :
- Definition : Stacking involves training multiple models and then using a meta-learner (another model) to combine their predictions.
- Objective : Leverages the strengths of different models by combining them in a hierarchical manner.
- How It Works :
- Base models (level-0 models) are trained independently on the training data.
- The predictions from these base models are used as input features to train a meta-learner (level-1 model).
- The meta-learner learns how to best combine the outputs of the base models to make the final prediction.
- Example : Using a linear regression model as a meta-learner to combine predictions from decision trees, SVMs, and neural networks.
- Applications : Kaggle competitions, where achieving the best possible accuracy is crucial.
4. Voting Ensembles :
- Definition : Voting ensembles involve training multiple models and combining their predictions using a voting mechanism.
- Objective : Aims to achieve better predictive performance by combining the outputs of different models.
- Types :
- Hard Voting : The final prediction is the class with the majority vote.
- Soft Voting : The final prediction is based on the average of predicted probabilities.
- How It Works :
- Each model is trained independently on the same training data.
- For classification tasks, the final output is determined by majority voting or averaging predicted probabilities.
- For regression tasks, predictions are averaged.
- Example : Combining logistic regression, SVM, and a decision tree for a classification problem.
- Applications : Spam detection, medical diagnosis, credit scoring.
5. Blending :
- Definition : A simplified version of stacking, where the predictions of base models are combined using a holdout set (a part of the training data).
- Objective : Similar to stacking but typically easier to implement as it uses a holdout set instead of cross-validation.
- How It Works :
- A portion of the training data is held out.
- Base models are trained on the remaining data and then used to make predictions on the holdout set.
- The holdout set predictions are used as input features to train the meta-learner.
- Example : Using different models to generate predictions on a validation set and then training a final model on these predictions.
- Applications : Predictive modeling when you want a simpler alternative to stacking.
6. Bootstrap Aggregation with Pasting :
- Definition : Similar to bagging, but instead of sampling with replacement, pasting samples without replacement.
- Objective : Reduces the variance of the models by training them on different portions of the data without overlap.
- How It Works :
- Data is sampled without replacement to create different subsets of the training data.
- Each subset is used to train a separate model.
- The final prediction is the average or majority vote of all models.
- Example : Using pasting to train multiple instances of decision trees.
- Applications : Useful when the training data is small, and overfitting is a concern.
7. Stacked Ensemble Learning with Cross-Validation :
- Definition : A variation of stacking that uses cross-validation to train the base models.
- Objective : Reduce overfitting by leveraging cross-validation in training.
- How It Works :
- Base models are trained using cross-validation, and their out-of-fold predictions are used as input features for the meta-learner.
- The meta-learner is then trained on these predictions.
- Example : Training decision trees, neural networks, and SVMs using cross-validation and using a linear model as the meta-learner.
- Applications : High-stakes predictive modeling tasks, competitions like Kaggle.
Advantages of Ensemble Methods:
- Improved Accuracy : Ensemble methods can significantly improve the predictive performance of models.
- Reduced Overfitting : Methods like bagging reduce overfitting by averaging out fluctuations.
- Flexibility : Ensemble methods can be applied to any type of model, making them versatile.
Disadvantages of Ensemble Methods:
- Complexity : They can be more complex to train, understand, and interpret.
- Computational Cost : Training multiple models can be computationally expensive, especially for large datasets.
When to Use Ensemble Methods:
- For High-Stakes Predictions : When accuracy is crucial (e.g., medical diagnosis, fraud detection).
- To Reduce Variance : When a single model tends to overfit the training data.
- In Competitions : Often used in competitions like Kaggle to push model performance to the limit.
Ensemble methods are powerful because they combine the strengths of multiple models, making them ideal for achieving high predictive accuracy and robustness across various machine learning problems.