Tokenization in NLP (Natural Language Processing)
Tokenization in NLP (Natural Language Processing)
What is Tokenization?
Tokenization is the process of taking a sentence or piece of text and breaking it down into smaller pieces, called tokens , that a computer can understand. This is the first step in making natural language (human language) understandable to a computer.
Tokens are essentially the building blocks of language that computers can analyze.
- Example:
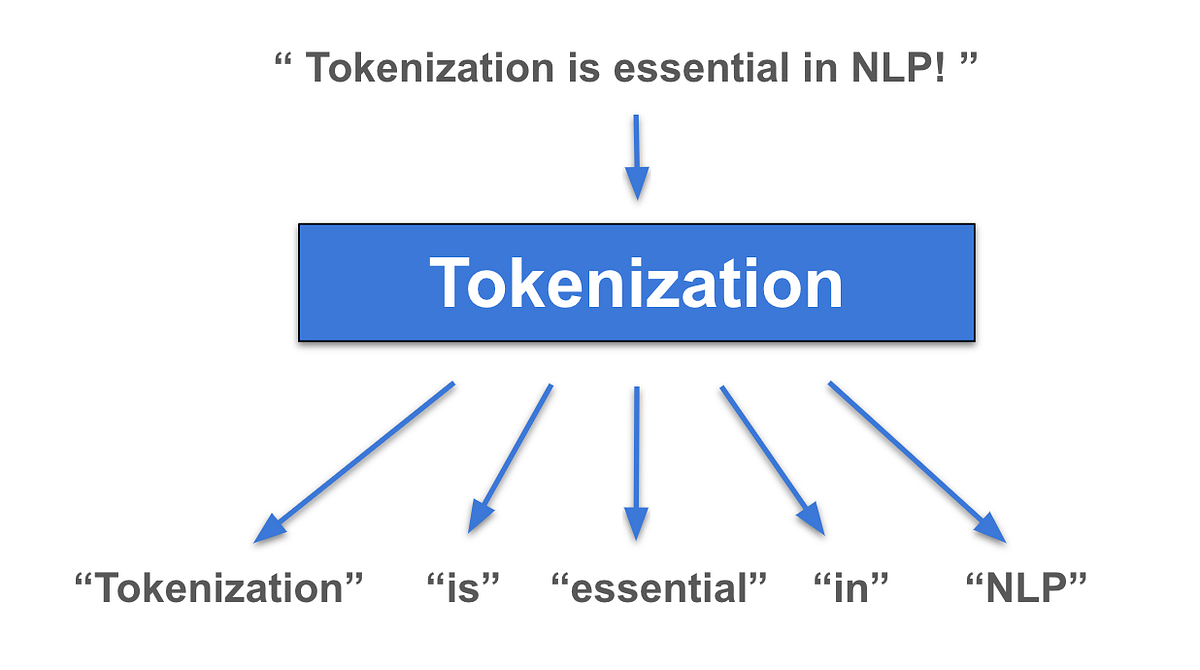
Text: "I love AI."
After tokenization: ["I", "love", "AI", "."]
In this case, each word ("I", "love", "AI") and the punctuation mark (".") become separate tokens.
- Example:
Why Tokenize Text?
Computers don’t naturally “speak” or “understand” human languages the way we do. Instead, they rely on mathematical and logical operations to process and interpret data. So, we need to break down complex sentences into pieces (tokens) that a computer can analyze.
- Goal: Tokenization helps a computer focus on individual parts of a sentence—like words or punctuation—so that it can process and understand the meaning of the text.
How Does Tokenization Work?
Tokenization works by splitting the text at spaces, punctuation, or other logical breaks. This allows a machine to process and understand individual elements within the text.
- Simple Example:
Text: "AI is awesome!"
Tokenized: ["AI", "is", "awesome", "!"]
Notice how each word and punctuation mark is treated as a separate token. This separation makes it easier for a computer to analyze each piece of the text individually.
- More Complex Example:
Text: "Tokenization is the process of splitting text into smaller pieces."
Tokenized: ["Tokenization", "is", "the", "process", "of", "splitting", "text", "into", "smaller", "pieces", "."]
Types of Tokenization
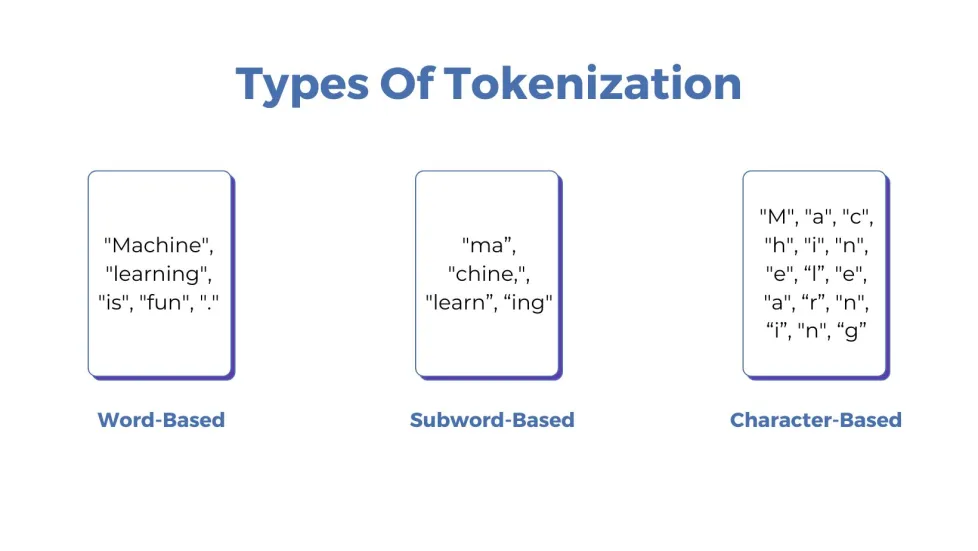
There are different ways to break down text into tokens depending on what we need to analyze. Here are the most common types of tokenization:
Word Tokenization
This type of tokenization splits text into individual words. It’s the most common form of tokenization used in NLP tasks.- Example:
Text: "I love programming."
Tokenized: ["I", "love", "programming"]
- Example:
Sentence Tokenization
Here, the text is broken down into complete sentences instead of just words. This is useful when we want to analyze the structure or meaning of entire sentences.- Example:
Text: "I love AI. It's amazing."
Tokenized: ["I love AI.", "It's amazing."]
- Example:
Subword Tokenization
In some cases, particularly for complex words or certain languages, words are broken down further into smaller parts (subwords). This helps when dealing with unfamiliar words or for handling spelling variations.- Example:
Word: "programming"
Tokenized: ["pro", "gram", "ming"]
- Example:
Character Tokenization
This type of tokenization splits the text down to individual characters. It’s useful for analyzing character-level features in the text or in languages where individual characters hold meaning.- Example:
Word: "AI"
Tokenized: ["A", "I"]
- Example:
Why is Tokenization Important?
Tokenization is essential because it helps computers “understand” text. Here’s why tokenization is so important:
Breaking Down the Complexity: Tokenization simplifies long sentences or paragraphs into smaller parts that a computer can more easily process.
Making Text Analyzable: Once text is tokenized, computers can analyze each token separately. This is crucial for tasks like:
Sentiment analysis: Determining if a sentence expresses a positive or negative emotion.
Machine Translation: Translating a sentence from one language to another.
Text Summarization: Creating a concise summary of a longer document.
Important for Machine Learning Models: Many machine learning models, like BERT or GPT , need tokenized text as input. Without tokenization, they cannot convert the text into the numerical data they need to process and learn.
Tokenization in AWS, Azure, and AI/ML
Now, let’s look at how AWS , Azure , and AI/ML use tokenization to process text:
AI/ML (Machine Learning):
AI Models (like GPT, BERT): Tokenization is the first step in processing text for machine learning models. For example, models like BERT and GPT use tokenization to convert human language into a numerical format that the machine can understand and process.
Example: If you’re training a model to generate text (like GPT), you need to tokenize your text data first, so the model can convert it into numbers and learn from it. Tokenization is what allows the model to “see” the meaning behind words, sentences, and paragraphs.
AWS (Amazon Web Services):
Amazon Comprehend: AWS provides a service called Amazon Comprehend , which uses tokenization for natural language processing (NLP) tasks. This service can break down text into tokens for tasks like sentiment analysis (positive or negative emotions) and entity recognition (identifying names, locations, etc.).
Example: You might use AWS Lambda to process customer reviews by tokenizing the text and then analyzing the sentiment (positive/negative) of the reviews.
Azure:
Azure Cognitive Services: Azure provides tools like Text Analytics API and Language Understanding (LUIS) that perform tokenization to break text into tokens for further analysis. These tools can recognize sentiments, identify entities, or detect the language of a text.
Example: Azure’s Text Analytics API tokenizes text from customer feedback and then analyzes it for keywords or to determine the overall sentiment of the feedback.
How Tokenization Helps in AI/ML Tasks:
Training AI Models: Tokenization helps prepare the input data for machine learning models, allowing them to process and learn from the text.
Understanding Context: By breaking down sentences into smaller tokens, the model can understand the relationship between different parts of the text, which helps improve accuracy in tasks like text generation, translation, or summarization.
Generating Predictions: After tokenization, the model can generate predictions or responses, such as predicting the next word in a sentence or translating text into another language.
Conclusion:
Tokenization is like the first puzzle piece in understanding and processing text. It breaks down complex sentences into smaller, meaningful parts that a computer can analyze and understand. Whether in AWS , Azure , or AI/ML , tokenization plays a key role in making sure machines can process language effectively and efficiently.