L8: Transformer, Tokenization, Embedding & Vectors
L8: Transformer, Tokenization, Embedding & Vectors
24:35
1. Unlabeled Data Processing
Definition:
Unlabeled data refers to datasets that lack predefined tags or labels. These datasets do not tell the model what each data point represents.
Example:
Imagine a collection of text from various articles, but none of them have labels like "Technology," "Sports," or "Health." This is unlabeled data.
How it's processed:
Self-Supervised Learning: The model learns patterns by predicting parts of the data based on other parts. For instance, in BERT , part of the sentence is hidden, and the model predicts the missing word.
Clustering: K-means clustering can group data into categories without needing labels.
2. How the Transformer Model Works
Definition:
The Transformer model is a type of deep learning model that processes sequences of data (like text) and focuses on the relationships between all words at once using self-attention.
Example:
For the sentence "The cat sat on the mat" , the Transformer doesn't read it left to right. Instead, it analyzes all the words simultaneously to understand how they relate to each other.
Key Concepts:
Self-Attention: Allows the model to determine which words are most important to each other.
Multi-Head Attention: Multiple attention heads capture different relationships between words in parallel.
3. Tokenization: Breaking Down Text
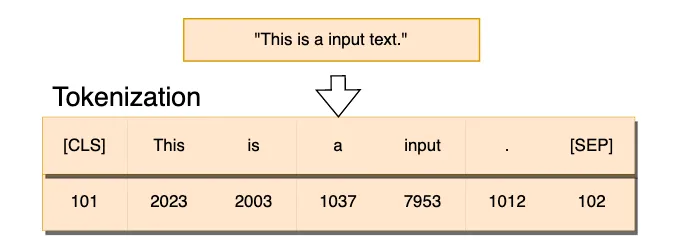
Definition:
Tokenization is the process of splitting text into smaller, manageable units, called tokens, which could be words or subwords.
Example:
Sentence: "The quick brown fox"
After tokenization: ["The", "quick", "brown", "fox"]
If a word is rare, it might be split into smaller parts:
Sentence: "Unhappiness"
After tokenization: ["Un", "happiness"]
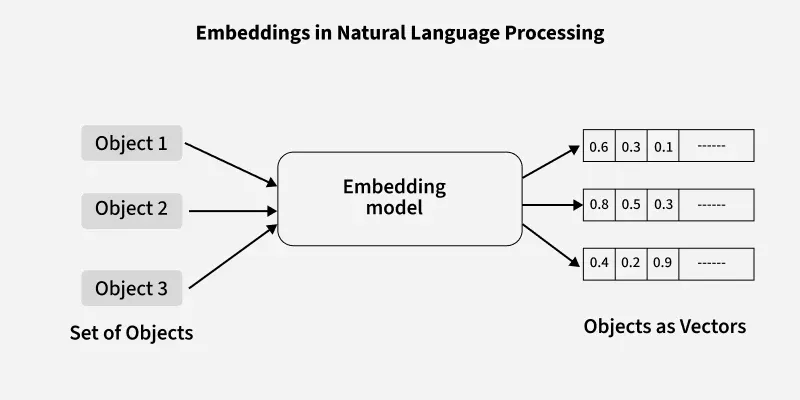
4. Vectors and Embeddings: Turning Words into Numbers
Definition:
Embeddings are vector representations of words, represented as numerical arrays that capture the meaning of a word based on its context.
Example:
For the word "dog" , its embedding in a 3-dimensional vector space could look like this:
- "dog" → [0.34, 0.52, -0.12]
These vectors are learned during training and allow the model to understand relationships between words. For example, "dog" and "puppy" will have similar vectors because they are related in meaning.

5. How the Transformer Uses Vectors and Self-Attention
Definition:
Once the text is tokenized and converted into embeddings (vectors), the Transformer uses self-attention to analyze how each word (token) relates to others in the sequence.
Example:
For the sentence “The cat sat on the mat” :
The word "cat" is closely related to "sat" , as the cat is performing the action of sitting.
The word "on" connects "sat" and "mat" to indicate the position.
Self-Attention Process:
The model calculates attention scores to decide which words have the strongest influence on others.
For example, "sat" might have strong connections to "cat" and "mat" , but weak connections to "on" and "the".
Multi-Head Attention:
- Multiple attention heads allow the model to capture different kinds of relationships simultaneously (e.g., grammatical structure, meaning).
6. Putting It All Together: Using Unlabeled Data
Definition:
Unlabeled data is processed by the Transformer model to learn the underlying patterns in text. Through tokenization, embedding, and self-attention, the model can understand text and perform tasks like translation, summarization, or text generation.
Process Overview:
Unlabeled Data : Provides raw information without labels, used for training models.
Tokenization : Breaks text into smaller units (tokens).
Embeddings : Convert words into vectors, representing their meaning.
Self-Attention : The Transformer model uses self-attention to find the relationships between words and understand their context.
In Summary:
Unlabeled Data helps the model learn without needing explicit labels.
Tokenization breaks down text into smaller chunks (tokens) for easier processing.
Embeddings represent words as numerical vectors, capturing their meanings.
Transformers use self-attention to understand relationships between words, making them powerful for complex tasks like translation, summarization, and more.
This structure should make the concepts clearer and easier to follow with appropriate examples.
Resources
Transformer Explainer (Poloclub)
Transformer