L6: Large Language Models (LLMs)
L6: Large Language Models (LLMs)
10:39
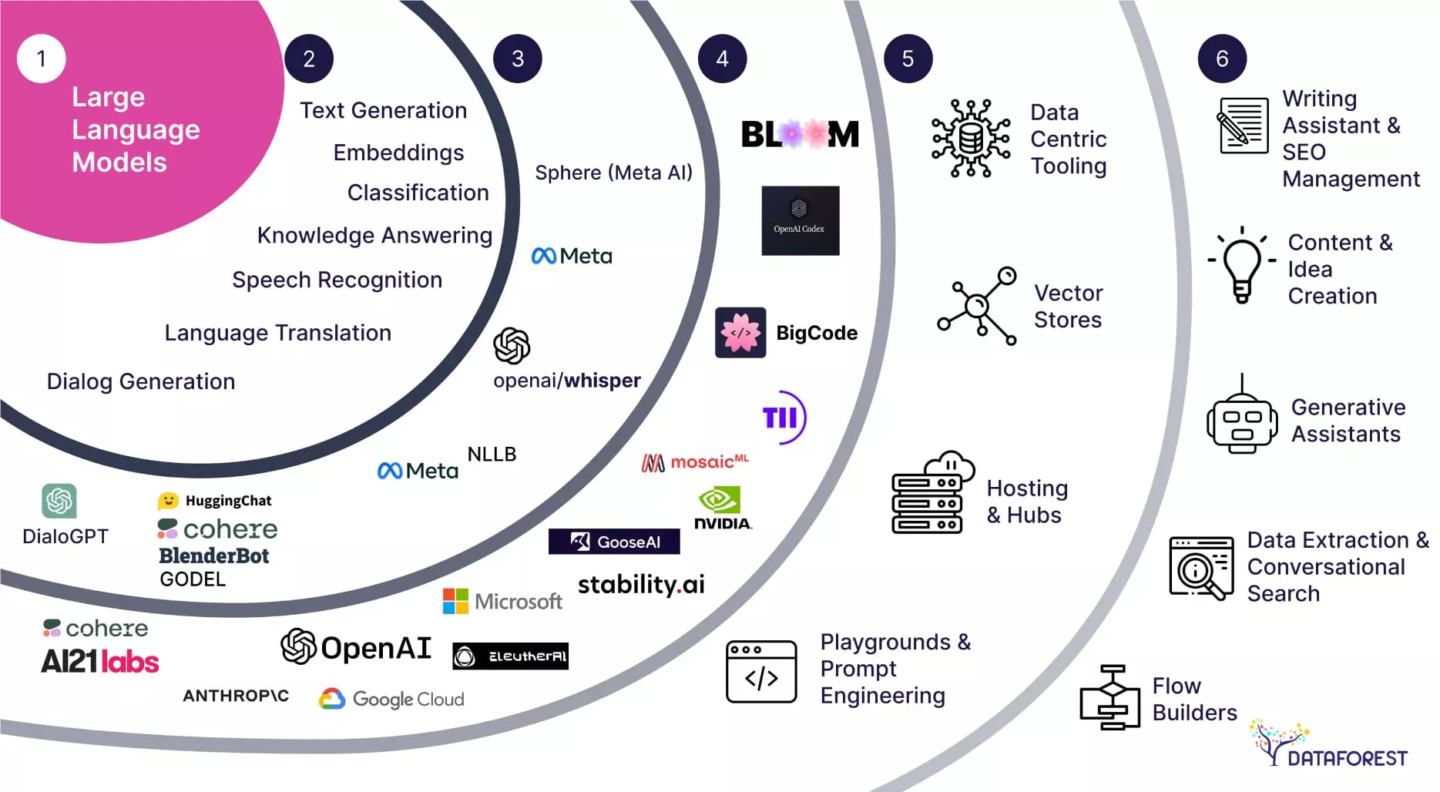
1 — Available Large Language Models
2 — General Use-Cases
3 — Specific Implementations
4 — Models
5 — Foundation Tooling
6 — End User UIs
Large Language Models (LLMs) are a type of artificial intelligence model designed to understand, generate, and manipulate human language. These models are based on deep learning techniques, particularly using architectures like transformers , and are trained on massive amounts of textual data to capture complex patterns in language.


Key Characteristics of Large Language Models (LLMs):
Massive Scale:
LLMs are typically characterized by having billions (or even trillions) of parameters. Parameters are the learned weights in the neural network that help the model predict and generate text.
The large number of parameters allows these models to understand and generate text in a highly sophisticated way, capturing nuances, context, and even generating human-like language.
Training on Large Datasets:
- LLMs are pre-trained on a vast corpus of text data. This data usually comes from diverse sources such as books, websites, academic papers, and social media. By being exposed to such a large and varied set of examples, LLMs can generalize their understanding to many different tasks.
Self-Supervised Learning:
The training process for LLMs often involves self-supervised learning , where the model predicts the next word in a sentence given the previous words (called causal language modeling), or it might predict a missing word in a sentence (like masked language modeling in models like BERT).
This approach helps the model understand syntactic and semantic structures in text without needing labeled data.
Contextual Understanding:
- LLMs excel in understanding the context of the text they are processing. They are capable of capturing long-range dependencies between words, understanding nuances in meaning, and handling ambiguity.
Transfer Learning and Fine-tuning:
- Once trained on large datasets, LLMs can be fine-tuned on specific datasets or tasks (like medical text or legal documents). Fine-tuning allows the model to adapt its knowledge to specific domains, making it more accurate for those tasks.
Types of Large Language Models:
Autoregressive Models:
These models predict the next token (word or sub-word) in a sequence, given the previous tokens.
Example: GPT (Generative Pre-trained Transformer) series by OpenAI, including GPT-3 and GPT-4.
They are typically used for tasks like text generation, dialogue systems, and completion tasks.
Masked Language Models:
These models predict missing tokens in a sequence, given the surrounding context. They are trained by masking parts of the input and teaching the model to predict the masked parts.
Example: BERT (Bidirectional Encoder Representations from Transformers) , designed for tasks like text classification, sentiment analysis, and question-answering.
Encoder-Decoder Models:
These models encode the input (usually a sentence or document) into a fixed-length representation and then decode that into an output sequence. They are particularly good for tasks where input and output sequences are of different lengths (e.g., machine translation).
Example: T5 (Text-to-Text Transfer Transformer) or BART.
Multimodal Models:
These models are capable of processing multiple types of data (e.g., text and images), making them useful for tasks that involve both modalities, such as image captioning or text-to-image generation.
Example: CLIP (Contrastive Language-Image Pretraining) and DALL·E from OpenAI.
Key Capabilities of LLMs:
Text Generation:
LLMs can generate coherent and contextually relevant text based on a prompt. For example, they can complete sentences, generate essays, or write stories.
They can adapt their style, tone, and content based on input prompts, which makes them useful for creative writing, marketing copy, and more.
Text Summarization:
LLMs can summarize long articles, papers, or documents into concise summaries while maintaining the core meaning.
They can perform both extractive summarization (picking key phrases or sentences) and abstractive summarization (generating a new, shorter summary).
Question Answering:
LLMs can answer specific questions based on a body of text. This is done by understanding the question's context and retrieving the relevant information from the given text.
This capability is useful in customer service chatbots, personal assistants, and knowledge retrieval systems.
Sentiment Analysis:
- By understanding the context and tone of a piece of text, LLMs can determine its sentiment (positive, negative, or neutral). This is widely used for social media analysis, product reviews, and customer feedback.
Translation:
LLMs can translate text from one language to another by understanding the meaning in the source language and producing an accurate translation in the target language.
Modern LLMs outperform traditional translation systems by capturing more nuanced meanings.
Text Classification and Named Entity Recognition (NER):
- LLMs can categorize text into predefined categories (such as spam detection or topic classification) and identify named entities (e.g., person names, dates, locations) within a text.
Conversational Agents:
- LLMs power chatbots and virtual assistants (like Siri, Alexa, or OpenAI's ChatGPT). They are capable of holding context over a conversation and provide intelligent responses to user queries.
Examples of Popular LLMs:
GPT-3/4 (Generative Pretrained Transformer):
- Developed by OpenAI , these are autoregressive language models known for their powerful text generation capabilities. GPT-4, for example, can generate creative writing, solve math problems, and even write code.
Hugging Face
BERT (Bidirectional Encoder Representations from Transformers) :
Developed by Google but**** hosted and made widely accessible by Hugging Face , BERT is designed to understand the context of words in a sentence by considering the words that come before and after them (bidirectional), , making it great for tasks like sentiment analysis and question answering.
Example Use Cases : Text classification, sentiment analysis, named entity recognition (NER), and question answering.
Claude (by Anthropic)
Claude 1, Claude 2, Claude 3 :
Claude is a family of LLMs developed by Anthropic , a company focused on AI safety. The Claude models are designed to be aligned with ethical AI principles and are built to be more interpretable and less likely to produce harmful outputs.
Example Use Cases : Conversational agents, content generation, ethical AI solutions.
LLaMA (by Meta/Facebook)
LLaMA (Large Language Model Meta AI) :
LLaMA is a series of LLMs created by Meta (formerly Facebook). It is designed to be smaller and more efficient than other models while still providing competitive performance across NLP tasks.
Example Use Cases : Text generation, question answering, and other language tasks with a focus on efficiency and scalability.
LLaMA has several versions: LLaMA-2 (with models ranging from 7B to 70B parameters) is the latest release.
T5 (Text-to-Text Transfer Transformer):
A model by Google that reframes all NLP tasks as text-to-text problems. It can handle tasks like translation, summarization, and question answering by converting them into a "text input" to "text output" format.
Example Use Cases : Text generation, translation, summarization, etc.
RoBERTa (Robustly optimized BERT approach):
- A variant of BERT , optimized for better performance. It's used in various NLP tasks like document classification, question answering, and summarization.
XLNet:
- An extension of BERT that integrates ideas from autoregressive models and is used for more robust text understanding and generation tasks.
Strengths of LLMs:
High Accuracy: Due to their vast size and complex architectures, LLMs can achieve state-of-the-art performance across many NLP tasks, sometimes surpassing human-level accuracy.
Versatility: They are highly adaptable, capable of solving multiple NLP problems with minimal modifications, including tasks like text generation, summarization, translation, and more.
Contextual Understanding: LLMs excel at understanding context, making them more accurate for tasks like question answering and dialogue generation.
Challenges with LLMs:
Resource Intensive:
- Training LLMs requires substantial computational power (e.g., multiple GPUs/TPUs), making them expensive to train and fine-tune.
Bias and Ethics:
- LLMs can inherit biases from the data they are trained on, which may result in biased or harmful outputs. Addressing this issue is an ongoing challenge in AI ethics.
Lack of Common Sense and Reasoning:
- While LLMs can generate text that sounds human-like, they still lack true understanding or common sense reasoning, which can result in nonsensical or misleading answers in some cases.
Interpretability:
- These models are often referred to as "black boxes," making it difficult to understand how they arrive at certain conclusions or predictions.
Conclusion:
Large Language Models represent a major breakthrough in AI, enabling machines to process and generate human language with high fluency and accuracy.
They are transforming industries like healthcare, finance, customer service, and entertainment by automating complex language tasks and enhancing human-computer interaction.
However, their challenges in terms of ethical concerns, computational cost, and interpretability remain important areas for future research and development.