L03: ML Lifecycle & Pieplines
L03: ML Lifecycle & Pieplines
6:27
- ML Workflow & Vertex AI >> https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform
What is the Machine Learning (ML) Lifecycle?
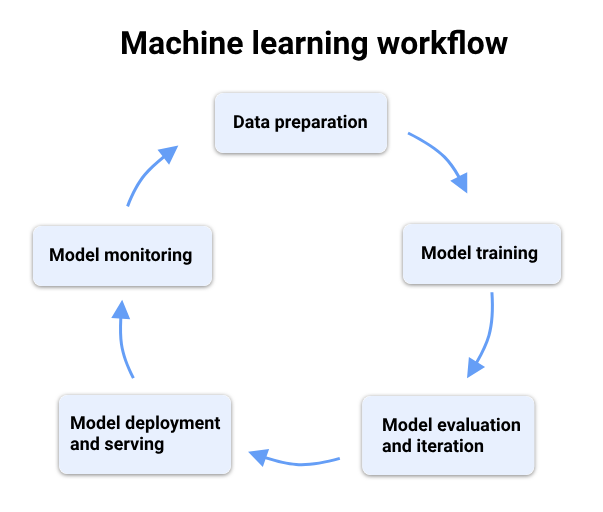
The ML lifecycle is the complete end-to-end process of building, deploying, and maintaining a machine learning model. It defines how raw data is transformed into a trained model that can make predictions in real-world applications.
In simple terms:
The ML lifecycle is the journey of a model from data collection to deployment and continuous improvement.
Key Stages of the ML Lifecycle
1. Problem Definition
Clearly define the business problem and what the model should predict or classify.
Example: Predict customer churn, detect fraud, recommend products.
2. Data Collection
Gather data from sources such as databases, sensors, logs, APIs, or cloud storage.
3. Data Preprocessing
Clean and prepare the data:
Remove missing values
Handle outliers
Normalize and encode features
Split into training and testing sets
4. Model Training
Train ML algorithms on prepared data to learn patterns.
Examples:
Linear Regression
Decision Trees
Random Forest
Neural Networks
5. Model Evaluation
Check performance using metrics:
Accuracy
Precision
Recall
F1-score
RMSE (for regression)
6. Model Deployment
Deploy the model to production using APIs, cloud services, or applications.
Example: Hosting on AWS SageMaker, Lambda, or Docker.
7. Monitoring & Maintenance
Continuously monitor:
Data drift
Model performance
Bias and errors
Retraining when accuracy drops
What is an ML Pipeline?
An ML pipeline is an automated workflow that connects all ML lifecycle steps into a single, repeatable process.
In simple terms:
An ML pipeline is an assembly line for building and running ML models automatically.
Components of an ML Pipeline
Data Ingestion
Data Transformation
Feature Engineering
Model Training
Model Validation
Model Deployment
Monitoring & Retraining
Why ML Pipelines Are Important
Automation – No manual repetition
Reproducibility – Same results every time
Scalability – Handles large datasets
Faster Deployment – CI/CD for ML (MLOps)
Reliability – Fewer human errors
Real-World Examples
Recommendation Systems: Continuous training on new user data
Fraud Detection: Real-time prediction pipelines
Voice Assistants: Model retraining using new speech data
Autonomous Vehicles: Sensor data → model update pipeline
Quiz
Q1. What is the main purpose of an ML pipeline?
A. To store data only
B. To automate and standardize the ML workflow
C. To visualize dashboards
D. To write application code
Correct Answer: B
Explanation: ML pipelines automate all steps from data processing to model deployment, ensuring consistency, speed, and reliability.
Q2. Which stage of the ML lifecycle focuses on checking model accuracy and performance?
A. Data Collection
B. Model Training
C. Model Evaluation
D. Model Deployment
Correct Answer: C
Explanation: Model evaluation uses metrics like accuracy, precision, and recall to measure how well the trained model performs before deployment.