Transformers
Transformers
Transformers are a type of deep learning architecture that has revolutionized natural language processing (NLP) and other fields like computer vision and audio processing. Introduced in the 2017 paper “Attention is All You Need” by Vaswani et al., transformers are highly effective at handling sequence-based tasks, such as language translation, text generation, and more.
Key Features of Transformers:
Self-Attention Mechanism :
The core innovation of the transformer architecture is self-attention (or scaled dot-product attention). This mechanism allows the model to weigh the importance of each word (or token) in a sentence relative to all the others, regardless of their position in the sequence.
In other words, self-attention enables the model to focus on relevant words when making predictions, even if those words are far apart in the sentence. This contrasts with traditional RNNs and LSTMs, which process sequences sequentially and struggle with long-range dependencies.
Example : In the sentence "The cat sat on the mat," when processing the word "sat," the model may use self-attention to focus on "cat" and "mat" to better understand the context.
Positional Encoding :
- Since transformers process all tokens in parallel (unlike RNNs, which process tokens sequentially), they need a way to incorporate the order of words in a sentence. This is achieved through positional encodings —vectors added to each token’s embedding to give the model information about the token’s position in the sequence.
Multi-Head Attention :
- Transformers use multi-head attention , where multiple attention mechanisms (heads) run in parallel. Each head learns a different aspect of the relationships between words in the sequence. The results are then combined to form a more comprehensive understanding of the sentence.
Feedforward Neural Networks :
- After the attention layer, the transformer uses a position-wise feedforward neural network (a simple fully connected layer) to process the data. This allows the model to learn complex representations of the input data.
Layer Normalization and Residual Connections :
- Transformers use residual connections (skip connections) around the attention and feedforward layers to prevent the vanishing gradient problem and allow for more effective training. Layer normalization is also applied to stabilize training.
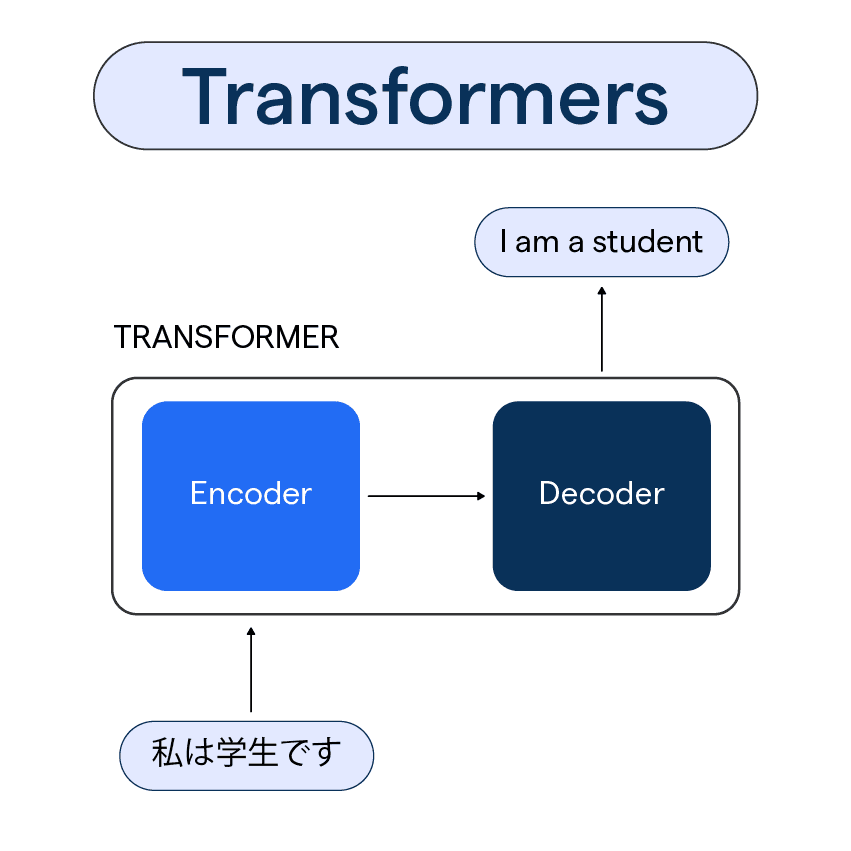
Transformer Architecture:
A typical transformer model consists of two main components:
Encoder :
- The encoder processes the input sequence and encodes it into a continuous representation that captures the relevant information. It consists of a stack of identical layers (usually 6 or more), each containing a multi-head self-attention mechanism followed by a feedforward neural network.
Decoder :
- The decoder generates the output sequence from the encoded representation. Like the encoder, the decoder is also composed of a stack of layers, but each layer contains an additional cross-attention mechanism, which attends to the encoder's output. The decoder is responsible for generating each token in the output sequence based on both the encoded input and previously generated tokens.
Transformer Variants:
BERT (Bidirectional Encoder Representations from Transformers) :
BERT is a pre-trained transformer model that focuses on bidirectional training, meaning it looks at both the left and right context of a word simultaneously. It is particularly effective for tasks like text classification, question answering, and named entity recognition.
Key feature : BERT uses a masked language model, where some words in a sentence are randomly hidden, and the model is trained to predict them based on the surrounding context.
GPT (Generative Pretrained Transformer) :
GPT, developed by OpenAI, is a unidirectional transformer model that is trained to predict the next word in a sequence, given the context of the words before it.
Key feature : GPT models are used primarily for text generation and autoregressive tasks, where the model generates text one token at a time.
T5 (Text-to-Text Transfer Transformer) :
T5 is a model that treats every NLP task as a text-to-text problem. For example, instead of distinguishing between tasks like translation and classification, T5 reformulates all tasks into text generation tasks.
Key feature : It uses the same architecture for all tasks, which allows it to generalize across a wide range of NLP problems.
XLNet :
XLNet improves upon BERT by learning bidirectional context while maintaining the autoregressive properties of GPT. It uses a permutation-based training method, allowing it to model all possible word orders.
Key feature : XLNet outperforms BERT on several benchmarks by considering the entire sequence’s permutations during training.
BART (Bidirectional and Auto-Regressive Transformers) :
BART combines the strengths of both BERT and GPT by using an encoder-decoder structure. It is useful for tasks like text generation, text completion, and machine translation.
Key feature : BART uses a denoising autoencoder approach for pre-training, where it corrupts input text and trains the model to recover it.
Applications of Transformers:
Natural Language Processing (NLP) :
Text classification : Classifying documents or sentences into categories (e.g., spam detection).
Named entity recognition (NER) : Identifying entities like names, dates, and locations in text.
Question answering : Answering questions based on a given text, as seen in models like BERT and T5.
Language translation : Translating text from one language to another using models like MarianMT and T5.
Text generation : Generating coherent and contextually relevant text, as seen in GPT models.
Computer Vision :
- Vision Transformers (ViTs) : Transformers can also be applied to image classification and segmentation tasks. Vision Transformers divide an image into patches and process them similarly to how transformers process sequences of words.
Speech Recognition :
- Speech-to-text systems : Transformers are being used in models like Wav2Vec for converting spoken language into written text.
Recommendation Systems :
- Transformers are used in recommendation models (such as Reformer) to generate personalized recommendations based on user behavior and preferences.
Code Generation :
- Models like Codex , a transformer-based model from OpenAI, can generate code based on natural language instructions.
Advantages of Transformers:
Parallelization : Unlike RNNs and LSTMs, which process tokens sequentially, transformers process all tokens in parallel, significantly improving training efficiency.
Handling Long-Range Dependencies : The self-attention mechanism allows transformers to effectively capture long-range dependencies in sequences, which is difficult for RNNs and LSTMs.
Scalability : Transformers are highly scalable and have been shown to perform well as they grow in size, enabling large models like GPT-3 with billions of parameters.
Transformers have become the foundation of modern NLP and are continuing to be adapted for use in other fields, such as computer vision, robotics, and audio processing, thanks to their versatility and efficiency.