NumPy, Matplotlib, Spark MLlib, Scikit-learn
NumPy, Matplotlib, Spark MLlib, Scikit-learn
NumPy
NumPy is a library for numerical computations in Python. It provides support for multi-dimensional arrays and matrices, which are essential for machine learning models.
Key Features of NumPy :
Efficient Array Operations : NumPy provides a fast and efficient way to perform operations on multi-dimensional arrays and matrices, which are essential for handling data in machine learning.
Integration with Frameworks : NumPy is heavily used in frameworks like TensorFlow and PyTorch for handling data preprocessing and manipulation before converting it into tensors.
Mathematical Functions : NumPy offers a wide range of mathematical functions, making it ideal for performing complex calculations needed in machine learning.
Use Cases for NumPy :
Data Preprocessing : NumPy is essential for handling numerical data, performing operations like scaling and reshaping data.
Array and Matrix Operations : NumPy is widely used for matrix multiplication and array manipulations in machine learning tasks.
If you want to know more about Numpy : click here
Matplotlib
Matplotlib is a Python library for data visualization. It is widely used to create static, animated, and interactive plots and charts, helping to visualize the results of machine learning models.
Key Features of Matplotlib :
2D Plotting : Matplotlib provides tools for creating a wide variety of 2D plots, including line charts, bar charts, histograms, and scatter plots.
Integration with NumPy and Pandas : Matplotlib integrates seamlessly with NumPy arrays and Pandas DataFrames, making it easy to visualize data before or after training machine learning models.
Customization : Matplotlib allows for a high degree of customization, enabling developers to create publication-quality visualizations.
Use Cases for Matplotlib :
Data Exploration : Matplotlib is used to visualize datasets and model performance metrics.
Model Evaluation : It helps visualize training loss, accuracy, and other important metrics during model training.
If you want to know more about Matplotlib :Click here
Spark MLlib
Spark MLlib is a machine learning library built on Apache Spark , a distributed computing framework. It’s designed for scalable machine learning tasks on large datasets.
Key Features of Spark MLlib :
Distributed Machine Learning : Spark MLlib is built for distributed machine learning, allowing models to be trained on large datasets across multiple machines.
Integration with Spark : Spark MLlib works seamlessly with other Spark components like Spark SQL and Spark Streaming , making it ideal for real-time machine learning tasks.
Algorithm Support : Spark MLlib includes a wide variety of machine learning algorithms, such as classification, regression, clustering, and collaborative filtering.
Use Cases for Spark MLlib :
Big Data Machine Learning : Spark MLlib is ideal for machine learning tasks that require processing large datasets.
Real-Time Analytics : When combined with Spark Streaming , MLlib can be used for real-time machine learning applications.
Scikit-learn
Scikit-learn is a Python library used for machine learning that provides simple and efficient tools for data analysis and modeling.
It is built on top of NumPy, SciPy, and matplotlib, and offers a wide range of algorithms for classification, regression, clustering, and dimensionality reduction.
Key Features of Scikit-learn:
1. Wide Range of Algorithms:
Scikit-learn provides a rich set of algorithms for machine learning, including:
- Classification (e.g., Logistic Regression, Decision Trees, Random Forests, SVM)
- Regression (e.g., Linear Regression, Lasso, Ridge)
- Clustering (e.g., K-Means, DBSCAN)
- Dimensionality Reduction (e.g., PCA, t-SNE)
- Model Evaluation (e.g., cross-validation, metrics for model performance)
2. Preprocessing Tools:
Scikit-learn includes a range of tools for data preprocessing, such as scaling, normalization, encoding categorical variables, and handling missing values, which are essential steps in the machine learning pipeline.
3. Model Selection and Hyperparameter Tuning:
Scikit-learn simplifies the process of model selection and hyperparameter tuning using tools like GridSearchCV and RandomizedSearchCV for automatic parameter optimization.
4. Pipeline Support:
The library supports the creation of pipelines, allowing for seamless chaining of preprocessing and modeling steps. This ensures reproducibility and easier model management.
5. Integration with Other Libraries:
Scikit-learn is designed to integrate seamlessly with other Python libraries, such as NumPy, pandas, and matplotlib, making it easier to perform end-to-end data analysis and visualization.
6. Model Evaluation:
It provides various methods to evaluate models, such as accuracy, precision, recall, F1 score, and confusion matrix, which are vital for assessing the performance of machine learning models.
Use Cases for Scikit-learn:
1. Data Preprocessing:
Scikit-learn’s preprocessing functions allow users to clean and transform data efficiently before feeding it into a machine learning model. This includes operations like feature scaling, encoding, and imputation.
2. Building and Training Models:
Whether for classification, regression, or clustering, Scikit-learn allows you to easily build and train models using various algorithms. It is commonly used for small- to medium-scale data problems.
3. Model Evaluation:
Scikit-learn provides functions to evaluate the performance of models, perform cross-validation, and generate performance metrics like confusion matrices, precision, recall, and ROC curves.
4. Prototyping and Research:
Thanks to its easy-to-use interface, Scikit-learn is popular in academia and research for quickly prototyping machine learning models and experimenting with different algorithms and techniques.
5. Hyperparameter Tuning:
Scikit-learn's grid search and random search tools are useful for improving model performance by fine-tuning hyperparameters.
If you want to know more about Scikit-learn , you can explore its official documentation for detailed tutorials, examples, and API reference.
NumPy vs SciPy vs Matplotlib vs Spark MLlib vs Scikit-learn
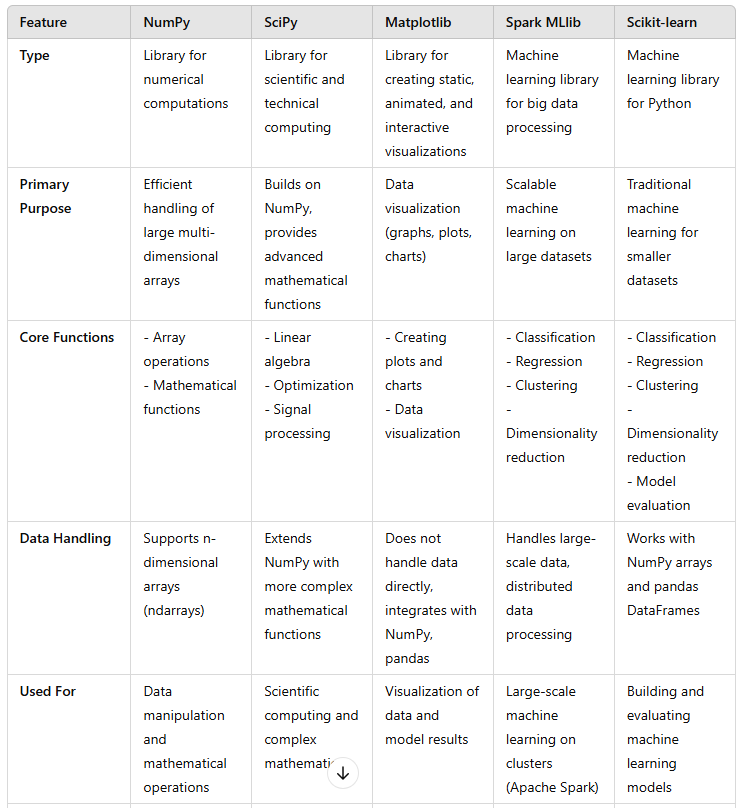
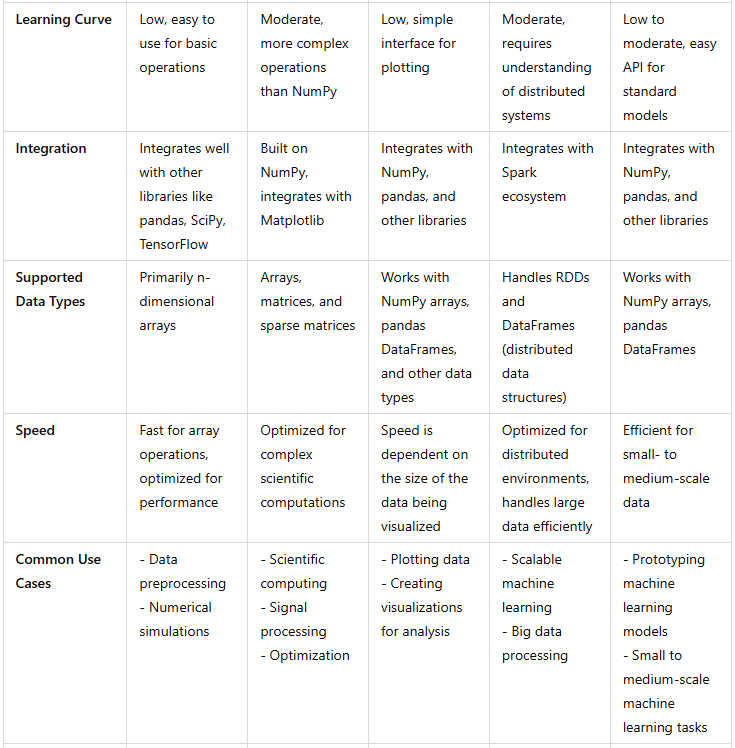
Key Differences:
NumPy is mainly for numerical data manipulation, SciPy extends NumPy with advanced scientific algorithms.
Matplotlib is solely for visualization, while the others focus on machine learning and data processing.
Spark MLlib is designed for large-scale distributed machine learning, unlike the other libraries, which are used for smaller datasets.
Scikit-learn is specifically built for machine learning and model evaluation, whereas the other libraries are either focused on data manipulation (NumPy, SciPy) or visualization (Matplotlib).