Q/A: Apache Spark & Apache Camel
Q/A: Apache Spark & Apache Camel
Apache Spark & Apache Camel:Traditional Use vs Cloud AI/ML (AWS & Azure)
APACHE SPARK
What is Apache Spark?
Apache Spark is an open-source, distributed data processing engine. It was created at UC Berkeley in 2009 and became an Apache project in 2010. Spark processes massive volumes of data by splitting the work across many computers (a cluster) simultaneously — this is called parallel computing.
Think of it this way: if you had to count 1 million words in a book, doing it alone would take hours. But if you split the book into 100 parts and gave one part to each of 100 people, the job would finish in minutes. That is exactly what Spark does — but with data and computers.
Core Architecture
**Driver Program: **The brain of a Spark application. It controls the overall job and breaks the task into smaller pieces.
**Cluster Manager: **Allocates computing resources (CPU, memory) across the cluster. Examples: YARN, Mesos, Kubernetes.
**Executors: **Worker machines that actually run the data processing tasks assigned by the driver.
**RDD (Resilient Distributed Dataset): **Spark's core data structure. It holds data split across multiple nodes and is fault-tolerant (if a node fails, data is recovered automatically).

How Was Spark Used Traditionally?
Before cloud computing became mainstream, organisations ran Spark on on-premise server clusters — physical machines they owned and maintained in their own data centres. Here are the key traditional use cases:
• Big Data Batch Processing: Companies like banks, retailers, and telecom providers collect massive transaction logs, clickstream data, or sensor readings. Spark would process these overnight in large batches — for example, generating daily reports on millions of customer transactions.
• Real-Time Streaming: Using Spark Streaming, organisations processed live data feeds — stock market prices, social media feeds, or IoT sensor data — in near real-time. This was used in fraud detection, real-time dashboards, and alerting systems.
• Traditional Machine Learning (MLlib): Spark's built-in ML library (MLlib) allowed data scientists to train classic ML models — regression, classification, clustering, recommendation engines — across distributed datasets that were too large for a single machine.
• Data Engineering Pipelines (ETL): Data engineers used Spark to build ETL pipelines: Extract data from source systems (databases, APIs, files), Transform it (clean, aggregate, join datasets), and Load it into a data warehouse or data lake for reporting.
• Spark SQL for Analytics: Analysts ran SQL queries on petabyte-scale datasets using Spark SQL, enabling BI reporting without needing a commercial database like Oracle or Teradata.
** PART 2 — APACHE CAMEL**
What is Apache Camel?
Apache Camel is an open-source integration framework. It was created in 2007 and is based on Enterprise Integration Patterns (EIPs) — a set of proven design patterns for connecting enterprise systems. Camel acts as a universal translator and router between different applications, systems, and protocols.
Think of Camel as a smart postal service inside a large organisation. Different departments speak different languages — one uses XML, another uses JSON, another uses a database table. Camel picks up messages from one place, translates them into the right format, and delivers them to the right destination automatically.
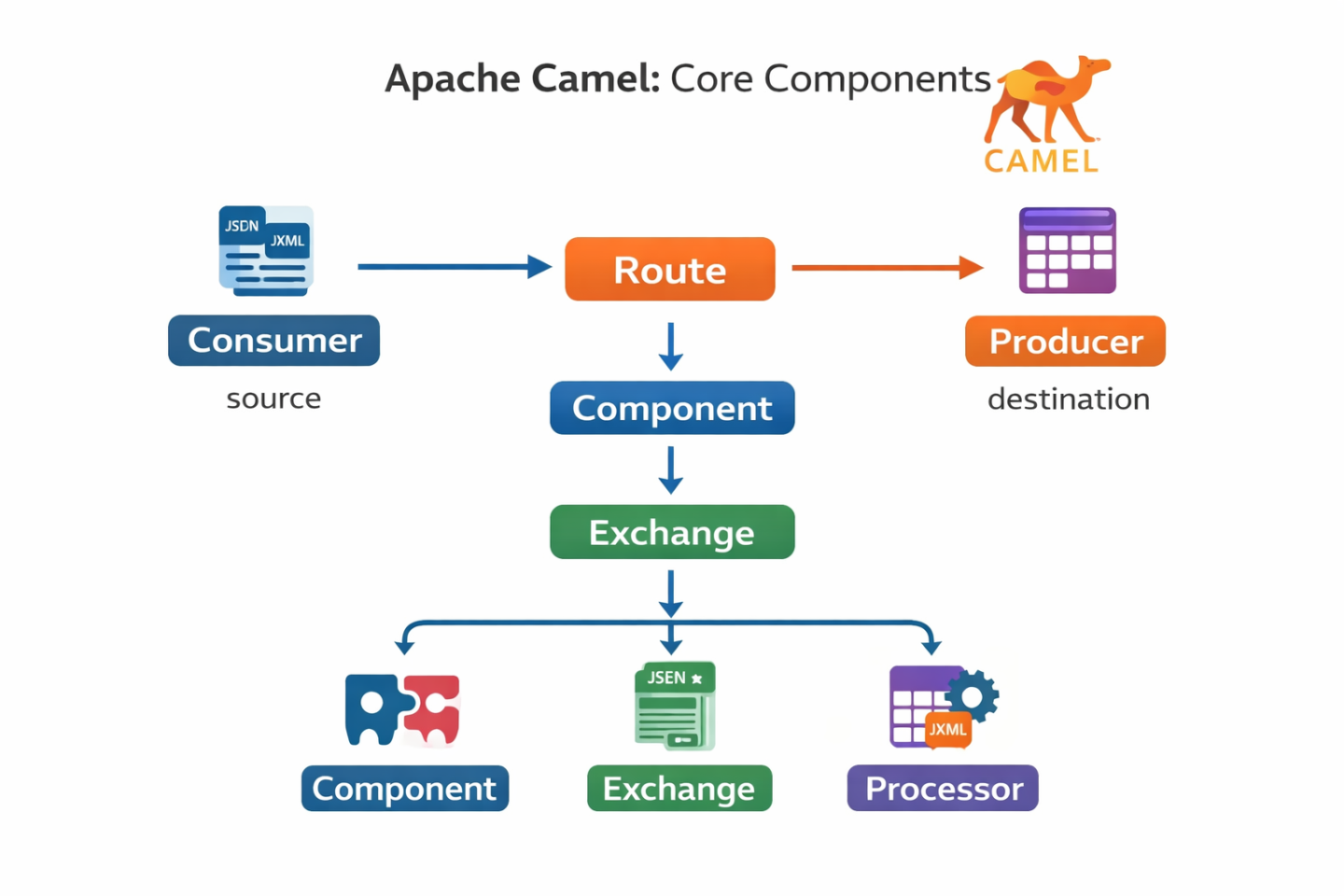
Core Concepts
**Route: **A defined path that a message travels from a source (consumer) to a destination (producer). For example: from('file:input') → to('database').
**Component: **A connector to a specific technology. Camel has 300+ built-in components for HTTP, FTP, JMS, Kafka, databases, email, SAP, Salesforce, and more.
**Exchange: **A container that holds the message being routed. Contains headers, body, and metadata.
**Processor: **A piece of logic that transforms or enriches a message as it travels through a route (e.g., convert XML to JSON, add a timestamp, validate data).
How Was Camel Used Traditionally?
Camel was the backbone of enterprise system integration, especially in industries like banking, insurance, healthcare, and government, where dozens of old and new systems needed to talk to each other.
• System-to-System Integration: Large banks might have 50+ internal systems — core banking, CRM, risk engines, payment gateways, reporting systems. Camel connected all these systems, routing data between them without rewriting any individual system.
• Legacy System Modernisation: Older mainframe systems spoke COBOL or used proprietary formats. Camel acted as a bridge between these legacy systems and newer REST APIs or microservices, allowing gradual modernisation without 'big bang' rewrites.
• Protocol Translation: Different systems use different communication protocols — FTP, SFTP, HTTP, HTTPS, JMS, AMQP, SOAP, REST. Camel translated between all of these automatically, so a system using FTP could talk to one using REST without any code change.
• Data Format Transformation: Camel converted data between formats on the fly — XML to JSON, CSV to Avro, EDI to XML — making it easy for systems with different data models to exchange information reliably.
• Microservice Orchestration: As organisations adopted microservices, Camel orchestrated the flow of data and events between dozens of small services, handling retries, error routing, dead-letter queues, and message splitting automatically.
** PART 3 — WHY NOT NEEDED IN THE CLOUD?**
The Shift from On-Premise to Cloud
When organisations ran Spark and Camel on-premise, they had to manage everything themselves: buy and rack servers, install operating systems, configure networking, patch software, handle failures, and scale manually. This required large IT infrastructure teams and significant capital investment.
Cloud platforms (AWS and Azure) have fundamentally changed this model. They offer fully managed services that handle all the infrastructure, scaling, security, and maintenance automatically. This eliminates the need to run Spark clusters or Camel integration servers manually.
Why Spark is Less Critical on Cloud
**✅ Managed Infrastructure: **Cloud services like AWS Glue and Azure Synapse run Spark-like jobs without you ever provisioning a cluster, installing Spark, or managing nodes.
**✅ Serverless Processing: **AWS Glue and Azure Data Factory are serverless — you pay only for what you use, and there is no idle cluster cost. Traditional Spark clusters ran 24/7 and were expensive.
**✅ Better ML Services: **AWS SageMaker and Azure ML offer purpose-built, fully managed ML platforms with AutoML, MLOps, model monitoring, and deployment — far more capable than Spark's MLlib for AI/ML workloads.
**✅ Native Integrations: **Cloud services are deeply integrated with storage (S3, Azure Data Lake), databases (RDS, Cosmos DB), and AI services — no manual wiring required.
**✅ No Cluster Management: **No need to size clusters, manage YARN, tune memory settings, or handle Spark version upgrades. Cloud services abstract all of this.
Why Camel is Less Critical on Cloud
**✅ Event-Driven Architecture: **Modern cloud architectures use managed event buses (AWS EventBridge, Azure Event Grid) that route events between services natively — no custom integration code needed.
**✅ Visual Workflow Tools: **Azure Logic Apps provides a drag-and-drop interface with 400+ connectors. What took weeks to build with Camel routes can be done in hours with no code.
**✅ Managed Messaging: **AWS SQS/SNS and Azure Service Bus replace Camel's message-based routing with fully managed, scalable queuing services that handle retries, dead-letter queues, and ordering automatically.
**✅ Native Microservice Support: **Cloud platforms natively support microservice communication through API Gateways, Service Meshes, and event buses — eliminating the need for a custom Camel integration layer.
**✅ No Protocol Complexity: **Cloud services standardise on HTTPS/REST and event-driven patterns. The protocol diversity that made Camel essential (FTP, SOAP, JMS, AMQP) is largely irrelevant in modern cloud-native apps.
**⚠️ Important Note: **Spark still exists on cloud through Azure Databricks and AWS EMR, but it is now abstracted and managed. You use Spark's power without managing Spark itself. The focus for Cloud AI/ML learners is on the higher-level services, not Spark internals.
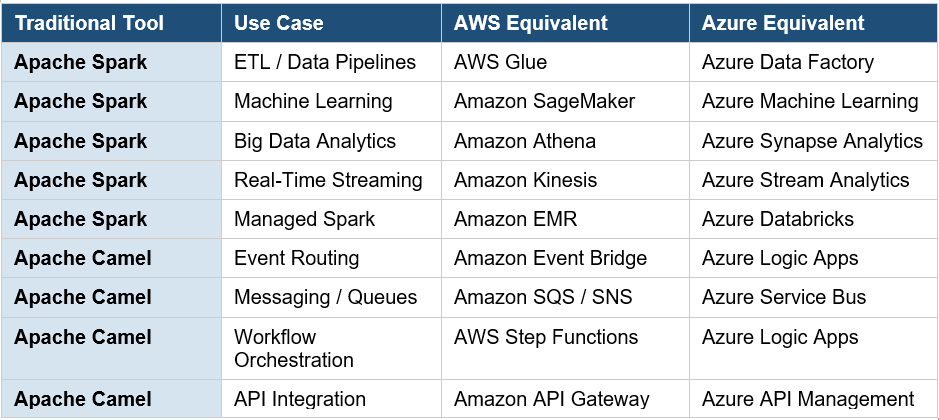
** PART 4 — CLOUD EQUIVALENT SERVICES**
Apache Spark → AWS Equivalents
**AWS Glue **Serverless ETL and data integration. Runs Spark jobs automatically. Best replacement for on-premise Spark data pipelines.
**Amazon SageMaker **End-to-end ML platform. Replaces Spark MLlib for all AI/ML model building, training, and deployment workloads.
**Amazon EMR **Managed Spark/Hadoop clusters on EC2. Use when you specifically need Spark with some level of manual control.
**Amazon Athena **Serverless SQL on S3. Replaces Spark SQL for analytics and ad-hoc querying on large datasets.
**Amazon Kinesis: **real-time streaming data ingestion and processing. Replaces Spark Streaming for live data pipeline workloads.
Apache Spark → Azure Equivalents
**Azure Synapse Analytics **Unified platform combining SQL, Spark, and ML. The most comprehensive replacement for traditional Spark-based data engineering.
**Azure Databricks **Managed Apache Spark on Azure. Best when Spark-specific features are needed, without the self-management overhead.
**Azure Machine Learning **End-to-end ML lifecycle. Replaces Spark MLlib for building, training, and deploying AI models on Azure.
**Azure Data Factory **Managed ETL pipelines and data movement. Replaces Spark-based transformation pipelines with a visual, code-optional tool.
Azure Stream Analytics: Real-time streaming analytics. Replaces Spark Streaming for processing live data from IoT, logs, and event sources.
Apache Camel → AWS Equivalents
**Amazon EventBridge **Serverless event bus. Routes events between AWS services, SaaS apps, and custom systems. Direct replacement for Camel routing.
AWS Step Functions: Visual workflow orchestration. Connects services into complex multi-step workflows. Replaces Camel's process orchestration.
**Amazon SQS / SNS **Managed queuing and pub/sub messaging. Replaces Camel's message routing and transformation patterns.
Amazon API Gateway: Manage, secure, and transform APIs. Replaces Camel's HTTP-based protocol translation and API routing.
Apache Camel → Azure Equivalents
**Azure Logic Apps **Low-code/no-code integration with 400+ connectors. The most direct visual replacement for Camel routes and integration flows.
**Azure Service Bus **Enterprise messaging platform with queues and topics. Replaces Camel's message-based enterprise integration patterns.
**Azure Event Grid **Managed event routing service. Replaces Camel's event-driven routing with a fully serverless, cloud-native solution.
**Azure API Management **Full lifecycle API gateway. Replaces Camel's API mediation, protocol transformation, and routing features.
** SUMMARY COMPARISON TABLE**